
04:00 is de tijd waarop de pluim gegenereerd wordt. Bij GFS duurt dit 10 uur na het beginnen van de berekeningen. De pluim van de 18z run wordt dus gemaakt om 04:00, en de pluim van de 6z run wordt gemaakt om 16:00. We kijken dus naar de 18z run hierboven.
Bij ECMWF gaat dit iets sneller, namelijk ruim 9 uur na het beginnen van de berekeningen. De 00z run krijgt bij EC dus om ongeveer 09:20 zijn pluim, en de 12z dus om 21:20.
Dan als kort antwoord op Winterfan:
GFS en EC verschillen van elkaar in de volgende dingen:
De bovenstaande zaken maken op de korte termijn weinig uit, als we spreken over 1 tot 3 dagen vooruit zijn GFS en EC vaak aan elkaar gelijk. Op lange termijn gaan de kleine verschillen in startwaardes, berekeningen en resolutie er wel toedoen, en dan kunnen we compleet verschillende situaties zien in GFS en EC.Startwaardes
1) Methode waarop input in het model gestopt wordt is verschillend tussen EC en GFS (dus de huidige toestand van de atmosfeer wordt op net verschillende manieren vergaard). De verschillen tussen alle groene lijntjes komen doordat de berekeningen met nét iets verschillende startwaardes opnieuw berekend wordt.
Resolutie
2) De EC oper (rode lijn in de pluim) berekent om de 9 km de toestand van de atmosfeer in 137 laagjes op verschillende hoogtes. De groene en blauwe lijntjes worden berekent om de 18 km met 91 lagen.
GFS is iets grover met een berekening iedere 13 km in 64 luchtlagen (na 240 uur of 10 dagen wordt GFS veel minder betrouwbaar met een berekening iedere 27 km).
Berekeningen
3) Verder zijn de natuurkundige formules achter de modellen precies hetzelfde bij EC en GFS. Sommige processen zijn echter te complex om precies te berekenen, hiervoor zijn er schattingen die de precieze processen na te bootsen. Deze schattingen (parameterisaties) zijn wél verschillend voor GFS en EC.
Voor deze pluimen specifiek zien we dat de oper berekeningen van elkaar verschillen, maar de groene lijntjes (het ensemble) van GFS en EC komen wel redelijk overeen. We kunnen dus zeggen dat de control berekening van GFS (blauwe lijn) voorlopig nog een uitbijter is.
| Gewijzigd: 5 januari 2021, 11:40 uur, door Thijs.
M.a.w. Leren de modellen van eerdere uitkomsten?
M.a.w. Leren de modellen van eerdere uitkomsten?
Ik heb de vragen over het weermodel even apart gezet omdat ik er op een later moment nog een groter artikel over wil schrijven, maar hier is een antwoord op je vraag (ik moest het ook even opzoeken hoe het precies zat):
Probleem: te weinig startgegevens voor een betrouwbaar weermodel

Hierboven zien we alle gebruikte data van het ECMWF voor automatisch en handmatige weerstations & meetinstrumenten voor vliegvelden en scheepvaart.

Alle gebruikte weerdata afkomstig van drijvende boeien (met de stroming meegaand) of vaste boeien.

Hierboven de data van vliegtuigen, ook een belangrijk onderdeel voor data van de hogere luchtlagen.
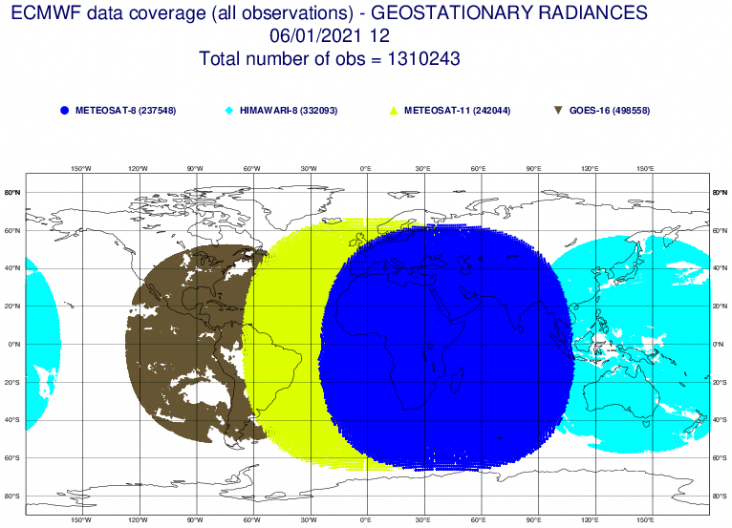
Hier zien de data van satellieten, de satellieten kunnen echter alleen van boven meten, dus wolken vormen vaak een obstakel. Ook kun je van boven alleen de maximale aanwezigheid van iets over de hele atmosfeer meten (bijvoorbeeld totale waterinhoud), en dit niet verdelen per luchtlaag (wat heel belangrijk is). Je weet dan namelijk niet of je waterdamp op 10 km zit (sluierbewolking) of op 0 meter (mist). Dit maakt voor ons een wereld van verschil.
Meteosat: ESA, zorgt voor het voor ons zo vertrouwde satellietbeeld van Europa.
GOES: satellietbeelden van de NASA.
Blader verder in de startwaarnemingen: https://www.ecmwf.int/en/forecasts/
We zien dus nog overal gaten in de data. Een weermodel heeft om te kunnen starten voor ieder hokje waarvoor iets berekend wordt (iedere 9 km voor EC) data nodig over wind, luchtdruk, vocht, temperatuur ect... En dat dan voor alle 91 luchtlagen!
De oplossing: Data-assimilatie
Wat de mensen achter de weermodellen hierop bedacht hebben, is het gebruiken van eerdere runs om de missende data aan te vullen. In een tijdspanne van vaak 24 uur wordt een weermodel dan aangepast aan de waarnemingen. Dit wordt data-assimilatie genoemd. Als ik het goed begrijp werkt dat als volgt:Voorbeeld:
De GFS run van 6 januari 12z verzameld zoveel mogelijk weerinformatie van de periode van 24 uur ervoor. Onder andere de voorgaande runs worden inderdaad vergeleken met de observaties die in de voorgaande 24 uur inmiddels binnen zijn gekomen. Via statistiek worden dan de gaten ingevuld met de (verbeterde) data van de voorgaande runs.
Het weermodel gebruikt de gegevens van de berekeningen uit de voorgaande 24 uur die het beste met de waarnemingen uit die periode overeenkomen.
Het KNMI schrijft:Informatie ECMWF: https://www.ecmwf.int/en/research/data-assimilation (ECMWF is wereldwijd toonaangevend als het gaat om data-assimilatie).
Waarnemingen binnen een bepaald tijdvenster (assimilation window, bijvoorbeeld 24 uur) worden gebruikt om een ongecorrigeerde modelontwikkeling (first guess) bij te sturen om de overeenkomst met de waargenomen toestand te verbeteren.
Lees meer: http://projects.knmi.nl/euclipse//Publications_siebesma.html/hurk_siebesma_ntvn.pdf
Dus, in het kort:
Dus modellen kijken niet naar vergelijkbare situaties uit een (ver) verlden, maar ze "leren" wel van de voorgaande 24 uur (omdat dit eigenlijk altijd de meest vergelijkbare situatie is met het heden). | Gewijzigd: 6 januari 2021, 21:25 uur, door Thijs.
Ik kan de vraag van Noorderzon wel snappen, daarin wijkt EC wel altijd aardig van GFS af.

^ Pluim van EC (ECMWF). De supercomputer achter dit model stond eerst in Reading (Engeland), maar is verhuist naar Bologna (Italië).

^ Pluim van GFS. De supercomputer achter dit model staat in de VS. Sommige weersites noemen dit model ook wel "de Amerikaan".
De pluimen die je bedoelde waren van EC (Europees model) en van GFS (Amerikaans model).
Verschillen tussen de modellen komen vooral door de volgende zaken:
- Verschil in de manier waarop weergegevens worden verzameld (technische term: data-assimilatie)
- Op welke manier worden de missende gaten opgevuld? Je kunt niet op iedere vierkante kilometer temperatuur, vocht ect.. meten. Dat kan al helemaal niet op alle verschillende luchtlagen (dan zou je permanent een drone met apparatuur op iedere kilometer moeten laten draaien). EC is vrij goed hierin, ze kunnen met nieuwe technieken een inschatting van de huidige staat van de atmosfeer maken. Je model is zo goed als de waardes die je hem geeft van de huidige staat van de atmosfeer (initial values). Dat is het meest belangrijk.
- Verschil in parameters
- De natuurwetten werken hetzelfde voor EC als GFS. Sommige processen zijn echter te complex, te klein, of begrijpen we nog niet goed genoeg. Van deze processen kunnen we dan een inschatting maken door er een parameter op de plakken. De kwaliteit van de inschattingen verschillen tussen de modellen.
- Verschil in resolutie tussen de weermodellen
- De modellen delen de wereld op in hokjes, die hokjes hebben een verschillende grootte in GFS en EC, zowel in hoogte als in oppervlak.